آشنایی با 7 نوع مدل داده و نقش آنها در هوش تجاری و انبار داده
- عباس فرمانی
- انبار داده, مقالات دسته علوم داده
- 2025/12/02
مقدمه: نقش هوش تجاری در تصمیمگیری سازمانی
در سالهای اخیر، «هوش تجاری» یا BI به یکی از مهمترین فناوریهای تصمیمیار در سازمانها تبدیل شده است. سازمانها با کمک هوش تجاری میتوانند حجم عظیمی از دادهها را تحلیل کرده و الگوهای رفتاری مشتریان، روند فروش، عملکرد بخشها و بسیاری از شاخصهای کلیدی دیگر را استخراج کنند. اساس کار هوش تجاری بر ایجاد ساختاری مناسب برای سازماندهی دادهها است و این ساختار معمولاً بر پایه انواع مدل داده یا همان data modelهای مختلف طراحی میشود.
هوش تجاری بدون یک انبار داده قدرتمند عملاً معنای کاملی پیدا نمیکند. هر چقدر ابزارهای تحلیل قوی باشد، اما دادهها ساختارمند، تمیز، تجمیعشده و استاندارد نباشند، نتایج تحلیل قابلاتکا نخواهند بود. بنابراین قبل از هر نوع تحلیل، BI نیازمند یک انبار داده مناسب بر اساس انواع مدل پایگاه داده و مخصوصاً انواع مدل سازی دادههای تحلیلی است.
در یک انبار داده، طراحی data model نقش زیربنایی دارد. تصمیمگیری درباره اینکه از کدام یک از انواع مدلهای داده استفاده شود—مثلاً مدل داده ستاره، مدل دانه برفی یا مدلهای دیگر مثل مدل کهکشانی—تأثیر مستقیمی بر کارایی سیستم، سرعت گزارشگیری، سادگی درک داده و مقیاسپذیری آینده دارد.
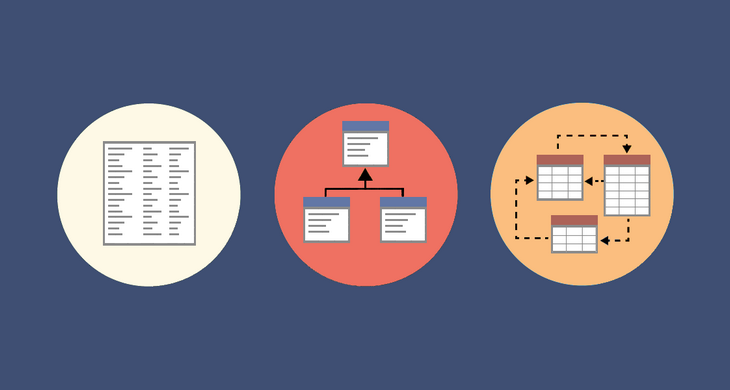
اهمیت انبار داده در هوش تجاری
انبار داده (Data Warehouse) محلی است که در آن دادههای عملیاتی از منابع مختلف جمعآوری، پاکسازی، استانداردسازی و ذخیرهسازی میشوند. هدف اصلی انبار داده این است که اطلاعاتی یکپارچه، تاریخچهدار، غیرقابلویرایش و مناسب تحلیل فراهم کند. این دادهها عموماً با استفاده از ابزارهای ETL مثل SSIS استخراج و وارد ساختارهایی میشوند که بر اساس انواع مدل دادهای طراحی شدهاند.
انواع data model در انبار داده بر اساس هدف تحلیل طراحی میشوند. برخی مدلها برای سرعت بیشتر بهینه شدهاند، برخی برای کاهش حجم دادهها، برخی برای سادگی درک و گزارشگیری و برخی برای انعطاف در تحلیلهای پیچیده. انتخاب درست میان star schema، snowflake schema و مدلهای ترکیبی (مثل مدل کهکشانی) یا سایر مدلهای داده مثل خزانه داده (Data Vault )، ER/3NF، Anchor Modeling، Wide Tables، میتواند کیفیت نهایی گزارشها را بهطور چشمگیری افزایش دهد.
وقتی انبار داده بهدرستی طراحی شود:
گزارشها سریعتر اجرا میشوند
تحلیلگران BI راحتتر به داده اعتماد میکنند
مدیران میتوانند تصمیمات دقیقتری بگیرند
سیستم کمتر نیازمند بازسازیهای پرهزینه میشود
به همین دلیل، آشنایی با انواع مدلهای داده ای و تفاوتهای آنها یکی از مهمترین بخشهای کار تحلیلگران داده و طراحان انبار داده است.
انواع مدل داده
در انبار داده معمولاً از مدلهای تحلیلی استفاده میشود که با OLAP سازگار هستند. اصلیترین انواع data model در این زمینه عبارتاند از:
مدل داده ستاره (Star Schema)
مدل دانه برفی (Snowflake Schema)
مدل کهکشانی یا مدل کنستلیشن (Galaxy / Constellation Schema
مدل های داده دیگری نیز هستند که ممکن است مناسب طراحی انبار داده نباشند؛ اما در این مقاله آنها را نیز بررسی می کنیم. اسن مدلهای داده به شرح زیر هستند:
- خزانه داده یا (Data Vault)
- ER/3NF
- Anchor Modeling
- Wide Tables
هر یک از این مدلها نوع مخصوصی از data model هستند و در شرایط مختلفی توصیه میشوند.
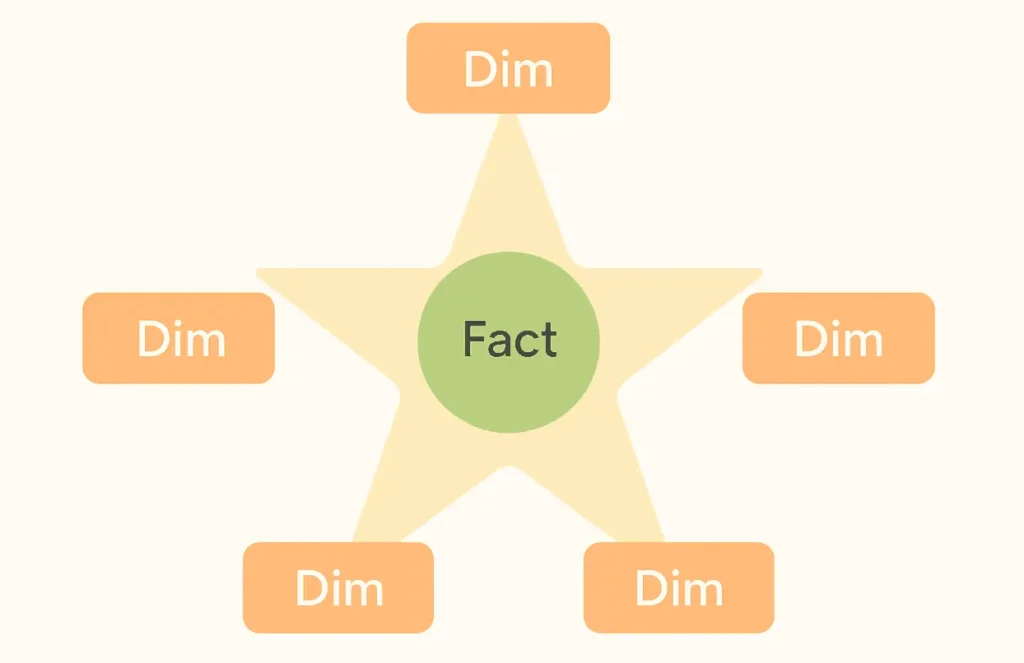
مدل داده ستاره (Star Schema)
مدل ستاره یکی از سادهترین و پرکاربردترین انواع data model در انبار داده است. در این مدل، یک جدول واقعیت در مرکز قرار دارد و چندین جدول بُعد آن را احاطه میکنند. این ساختار باعث میشود گزارشگیری بسیار سریع انجام شود، زیرا تعداد joinها کم است و دادهها در ابعاد به صورت denormalized ذخیره میشوند.
مدل ستاره در سیستمهای داشبوردی، گزارشهای روزانه و تحلیلهای سبک سریعترین عملکرد را ارائه میدهد و به دلیل سادگیاش برای کاربران غیرتخصصی هم بسیار قابل درک است. با این حال وجود دادههای تکراری در ابعاد و نیاز به فضای ذخیره بیشتر، از نقاط ضعف آن محسوب میشود.
ساختار جدولهای مدل ستاره
Fact Table یا جدول فکت: شامل مقادیری مثل تعداد فروش، مبلغ فروش، سود، تعداد تماس، تعداد بازدید و …
Dimension Tables یا جدول دایمنشن : شامل مشخصات توضیحی مانند:
بعد مشتری (نام، سن، جنسیت، منطقه)
بعد محصول (نوع محصول، برند، دستهبندی)
بعد زمان (سال، ماه، روز)
بعد فروشنده (کد فروشنده، منطقه کاری، سطح تجربه)
این ساختار یکی از محبوبترین انواع مدل های داده است زیرا:
درک آن برای کاربران بسیار ساده است
گزارشگیری سریع انجام میشود
joinها کم است
مناسب برای دیتاستهای بزرگ است
مدل دانه برفی (Snowflake Schema)
مدل دانه برفی، نسخه نرمالشده مدل ستاره است و ابعاد آن به چند جدول فرعی تقسیم میشوند تا تکرار داده کاهش یابد. این مدل برای سازمانهایی با دادههای پیچیده و روابط چندسطحی مناسب است و ذخیرهسازی بهینهتری نسبت به مدل ستاره ارائه میدهد. هرچند تعداد joinها بیشتر است و این امر میتواند سرعت گزارشگیری را کاهش دهد، اما مدیریت دادهها در ابعاد پیچیده را سادهتر میکند و کیفیت دادههای تاریخی را حفظ میکند.
چرا نام آن دانه برفی است؟
چون ساختار گرافیکی آن شبیه یک دانهٔ برف با شاخههای متعدد است.
ساختار جدولهای مدل دانه برفی
Fact Table همانند مدل ستاره
Dimension Tables
بخشبندی شده به چند جدول کوچکتر
مثال:
جدول محصول ← جدول برند ← جدول دستهبندی
جدول منطقه ← جدول کشور ← جدول قاره
این مدل یکی از انواع مدل داده ای است که برای موارد زیر مناسب است:
کاهش حجم ذخیرهسازی
مدیریت دادههای ابعادی پیچیده
کنترل تکرار دادهها
البته joinهای بیشتری دارد و ممکن است سرعت کاهش یابد.

مدل کهکشانی (Galaxy / Constellation Schema)
مدل کهکشانی زمانی استفاده میشود که چند فرآیند کلیدی در سازمان وجود دارد و هر کدام Fact Table مخصوص به خود را دارند. این مدل معمولاً شامل ابعاد مشترک است که بین چند Fact Table استفاده میشود و ساختاری منعطفتر از ستاره و دانه برفی ایجاد میکند.
این مدل مناسب کسبوکارهای بزرگ و چندبعدی است که مجموعهای از فرآیندها مانند فروش، انبار، حملونقل و تولید دارند. با اینکه طراحی آن پیچیدهتر است، اما قدرت تحلیل بسیار متنوعی فراهم میکند و برای انبار دادههای عظیم گزینهای ایدهآل محسوب میشود.
این مدل معمولاً در سیستمهایی استفاده میشود که چندین فرآیند اصلی دارند. برای مثال در یک سازمان خردهفروشی:
Fact Table فروش
Fact Table انبار
Fact Table حملونقل
و ابعاد مشترکی مثل مشتری، محصول، زمان و … وجود دارد.
این مدل ترکیبی از star schema و snowflake schema است و انعطافپذیری بیشتری نسبت به دیگر انواع data model فراهم میکند.

مدل Data Vault 2.0
Data Vault 2.0 یا خزانه داده، یکی از انواع مدل داده مدرن است که تمرکز آن روی انعطافپذیری، مقیاسپذیری و ردیابی تغییرات تاریخی است. این مدل داده را به سه بخش Hub، Link و Satellite تقسیم میکند.
Hubها اطلاعات کلیدی و یکتا را ذخیره میکنند، Linkها روابط بین Hubها را نشان میدهند و Satelliteها اطلاعات توصیفی و تاریخچهدار را نگه میدارند. این مدل بهدلیل ساختار ماژولار خود برای سازمانهایی که منابع دادهای متعدد و دائما در حال تغییر دارند بسیار منسب است. Data Vault 2.0 بهصورت طبیعی تاریخچهٔ کامل داده را حفظ میکند و برای محیطهای Big Data یا سامانههای چابک بسیار کارآمد است.

مدل داده به روش لنگر یا Anchor Modeling
Anchor Modeling یا مدل سازی لنگر، رویکردی مدرن برای مدلسازی داده و یکی از انواع مدل داده است که بر انعطافپذیری و تغییرپذیری ساختار تاکید دارد. این مدل با رویکرد Dimensional تفاوت دارد اما برای ساخت انبار داده می تواند مورد استفاده قرار گیرد. دادهها به سه بخش Anchor، Attribute و Tie تقسیم میشوند. Anchorها موجودیتهای اصلی هستند، Attributeها ویژگیها و توضیحات را ذخیره میکنند و Tieها روابط میان موجودیتها را نمایش میدهند.
این مدل به طور طبیعی تاریخچه داده را پشتیبانی میکند و تغییرات ساختاری را به راحتی مدیریت میکند. Anchor Modeling برای سیستمهایی که تغییرات مداوم و پیچیده دارند بسیار مناسب است و طراحی آن نسبتاً ماژولار است.
اگر اطلاعات دقیقی در مورد فرآیندهای کسب و کار و انعطافپذیری مدلسازی مورد نیاز باشد، مدلسازی لنگر بهترین انتخاب است.اگر تجزیه و تحلیل سریع و سادگی پیادهسازی مورد نیاز باشد، مدل ابعادی راهحل مناسبتری است.
جداول عریض یا Wide Tables
مدل Wide Table که یکی از انواع مدل داده است و رویکرد جدید برای ذخیره سازی داده است؛ شامل جداول بسیار عریض با تعداد زیادی ستون است که اغلب ابعاد مختلف در یک جدول تجمیع شدهاند. این مدل به دلیل کاهش نیاز به join، سرعت تحلیل را به شکل چشمگیری افزایش میدهد و برای پردازشهای ابری، پردازش ستونی و ماشینلرنینگ ایدهآل است. نقطه ضعف آن بزرگ شدن حجم جدول و سختتر شدن مدیریت Metadata و تغییرات است. Wide Tables بیشتر در سیستمهای cloud-based و Big Data کاربرد دارد.
در این مدل از جداول غیر نرمال به صورت ساختار فلت استفاده می شود به این مدل OBT یا One Big Table نیز می گویند.

مدل ER/3NF
مدل ER/3NF یکی از انواع مدل داده رابطهای نرمالشده است که تمرکز آن بر حذف تکرار دادهها و حفظ صحت اطلاعات است. این مدل برای سیستمهای عملیاتی (OLTP) طراحی شده و در مرحله استخراج و ذخیرهسازی اولیه دادهها کاربرد دارد. ساختار آن شامل تعداد زیادی جدول مرتبط با کلیدهای خارجی است که صحت داده را تضمین میکند. با وجود این، برای تحلیلهای OLAP مناسب نیست زیرا تعداد joinها زیاد است و سرعت پاسخدهی کاهش مییابد. معمولاً قبل از تبدیل دادهها به مدلهای تحلیلی، دادهها ابتدا در ER/3NF ذخیره میشوند.
مقایسه مدلهای داده و مزایا و معایب
مدل ستاره ساده، قابل فهم و سریع است، مناسب داشبوردها و کاربران غیرتخصصی، اما دادهها در ابعاد تکراری هستند.
مدل دانه برفی دقیقتر و نرمالشده است، حجم ذخیرهسازی بهینه دارد و برای دادههای پیچیده مناسب است، ولی سرعت گزارشگیری پایینتر است.
مدل کهکشانی انعطافپذیری بالایی دارد و برای تحلیل چند فرآیند همزمان مناسب است، اما طراحی پیچیدهای دارد.
Data Vault 2.0 مقیاسپذیر و تاریخچهمحور است و تغییرات ساختاری را به خوبی مدیریت میکند، ولی تحلیل مستقیم روی آن نیازمند تبدیل به مدلهای ستارهای یا Martهاست.
مدل ER/3NF از نظر صحت و یکپارچگی داده عالی است، اما برای تحلیلهای OLAP کند و دشوار است.
Anchor Modeling انعطافپذیری بالا و مدیریت آسان تغییرات را فراهم میکند، ولی برای تحلیل مستقیم نیاز به تبدیل به مدل تحلیلی دارد.
Wide Tables سرعت تحلیل فوقالعادهای ارائه میدهد، مخصوصاً در پردازش ابری و Big Data، اما مدیریت جدولهای عریض و تغییرات سختتر است.
به طور خلاصه، اگر هدف سرعت و سادگی است مدل ستاره بهترین گزینه است، برای بهینهسازی ذخیرهسازی مدل دانه برفی مناسب است، برای محیطهای پیچیده و چندفرآیندی مدل کهکشانی و برای مقیاسپذیری و تغییرات زیاد، Data Vault 2.0 و Anchor Modeling انتخابهای عالی هستند. Wide Tables نیز برای پردازشهای ابری و ماشینلرنینگ بهترین عملکرد را ارائه میدهد.